เบื้องหลังการทำงานของ Kubernetes คือ Linux (Kubernetes is just Linux)
เคยสงสัยกันไหมครับว่า Kubernetes เกี่ยวข้องอย่างไรกับ Linux บ้าง? ทำไมพื้นฐานของ Linux จึงมีความสำคัญกับเครื่องมือหรือแอปพลิเคชันหลายๆ อย่าง? และหนึ่งในนั้นคือ Kubernetes
ตามที่ทุกคนทราบกันดีว่า Kubernetes (หรือที่เรียกสั้นๆ ว่า k8s) เป็นเครื่องมือที่ถูกออกแบบมาเพื่อจัดการการทำงานต่างๆ ของแอปพลิเคชันที่รันอยู่ใน container หรือที่เรามักเรียกว่า container orchestrator เช่นเดียวกับ Apache Mesos และ Docker Swarm ซึ่งปัจจุบัน Kubernetes ก็กำลังได้รับความนิยมอย่างมาก อย่างไรก็ตาม หลายคนอาจมองว่า Kubernetes มีความซับซ้อนและเป็นเรื่องยากที่จะเข้าใจการทำงานของมัน แต่ความจริงแล้ว หากได้ลองศึกษาและทำความเข้าใจกับมันจริงๆ จะพบว่าเบื้องหลังของ Kubernetes คือการทำงานของ Kubernetes engine ร่วมกับชุดการทำงานต่างๆ ที่อยู่บน fundamental ของ Linux ไม่ว่าจะเป็น pod, container, Service, Ingress และ Persistent Volume ล้วนแล้วแต่เป็นสิ่งที่ Kubernetes service เรียกใช้บริการหรือชุดคำสั่งของ Linux ทั้งสิ้น

บทความนี้ผมจะมาเจาะลึกให้เห็นว่า Kubernetes และ Linux มีความเกี่ยวข้องกันอย่างไรบ้าง
1. Pod และ Container:
Pod ถือเป็นหัวใจสำคัญและเป็นหน่วยที่เล็กที่สุดของ Kubernetes โดย pod เปรียบเสมือนสิ่งที่ห่อหุ้ม container ตั้งแต่ 1 container ขึ้นไปไว้ภายใน pod จะแยกทรัพยากรต่างๆ เช่น Network Interface, Volume และ Process ออกจาก pod อื่นๆ อย่างชัดเจน
ส่วน container ภายใน pod เดียวกันจะมีการใช้ Network Interface และ Volume ร่วมกัน รวมถึงการติดต่อสื่อสารระหว่างกันก็จะเกิดขึ้นเฉพาะภายใน pod นั้นเท่านั้น

แล้ว container นั้นถูกสร้างขึ้นได้อย่างไร? แล้ว pod ทำการแยกทรัพยากรแบบนั้นได้อย่างไร?
หลายคนอาจจะคิดว่า Container engine อย่าง Docker, Containerd หรือ CRI-O เป็นตัวที่สร้าง Container ขึ้นมาให้เรา แต่ความจริงแล้ว เบื้องหลังของทั้งหมดนี้เกิดจากความสามารถพื้นฐานของ Linux Kernel ที่เรียกว่า Namespace และ Cgroup
1.1 Namespaces : ( คนละความหมายกับ Namespace ใน Kubernetes ) Linux namespace เป็นเครื่องมือที่ทำให้เราสามารถแบ่ง partition หรือ isolate kernel resource ต่างๆ ออกจาก process หรือ container อื่นๆ ได้ โดยภายใน Namespace เดียวกัน แต่ละ process จะมองเห็น resource ต่างๆ เหมือนกัน
โดยประเภทของ Linux namespace ที่เลือกนำมาจัดการ Container มีดังนี้
- Mount (MNT) namespaces: จัดการเกี่ยวกับ mount tables เพื่อทำให้การ mount หรือ unmount folder ไม่กระทบกับ namespace อื่น
- Network (NET) namespaces: จัดการ network stack (network device, IP protocal, port number, อื่นๆ) สำหรับ process
- PID namespaces: จัดการให้ process ID เป็นอิสระออกจาก process ใน namespace อื่นๆ หรือพูดง่ายๆคือ ทำให้ process มองเห็น process อื่นๆใน namespace เดียวกันเท่านั้น โดย process แรกที่ถูกสร้างใน namespace จะเริ่มเป็น PID 1
- IPC namespace: จัดการเรื่องการติดต่อสื่อสารระหว่าง process ภายใน namespace เพื่อไม่ให้ process จาก namespace อื่นๆ มาใช้งาน process ได้
- User namespaces: จัดการ user ID และ group ID ภายใน namespace
- UNIX Time-Sharing (UTS) namespaces: จัดการเรื่องของ hostname และ NIS domain name
1.2 Control groups (Cgroups): เมื่อเราสามารถแยก process โดยใช้ Linux namespace ได้แล้ว cgroup จะเป็นกลไกที่ช่วยจัดการควบคุมการใช้ system resource (CPU, RAM, Block I/O, Network, อื่นๆ) ในแต่ละ namespace เพื่อให้เราสามารถจำกัด (limit) การใช้ resource เหล่านั้นให้กับแต่ละกลุ่มของ process ได้
โดยมี 4 คุณสมบัติของ cgroup ที่เกี่ยวข้องกับ container workload ดังนี้
- Resource Limiting: ควบคุมขอบเขตการใช้งาน system resource
- Prioritization: จัดลำดับความสำคัญ (priority) ว่า process ใดควรจะได้เวลาในการใช้ system resource มากกว่ากัน
- Accounting: จัดการบัญชีของ process ใน cgroup และตรวจสอบว่า process ใดใช้ system resource ใดบ้าง และใช้ไปเท่าไหร่
- Process Control: จัดการแต่ละกลุ่มของ process ในการเข้าใช้งาน system resource
ประเภทของ resource ที่ cgroup สามารถ limit ได้
- Storage (blkio)
- Processor scheduling (cpu)
- Memory Usage (memory)
- Network Bandwidth (net_cls)
- Network traffic priority (net_prio)
- Namespace (ns)
- etc.
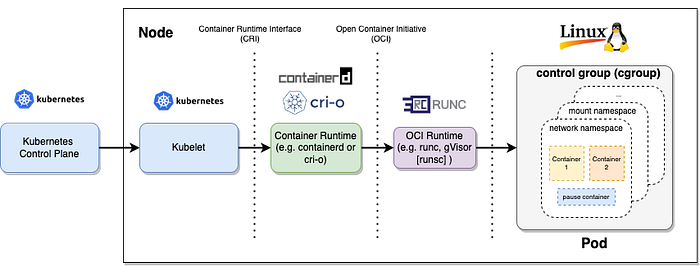
“Container are just collection of processes”
2. Resource Limit
การจำกัด (limit) resource ต่างๆ ของ pod จะถูกจัดการด้วย cgroup โดย configuration ทั้งหมดจะอยู่บน host path /sys/fs/cgroup ซึ่งภายใต้ directory นี้จะเป็นการแยกประเภทของ resource ที่ cgroup จัดการอยู่
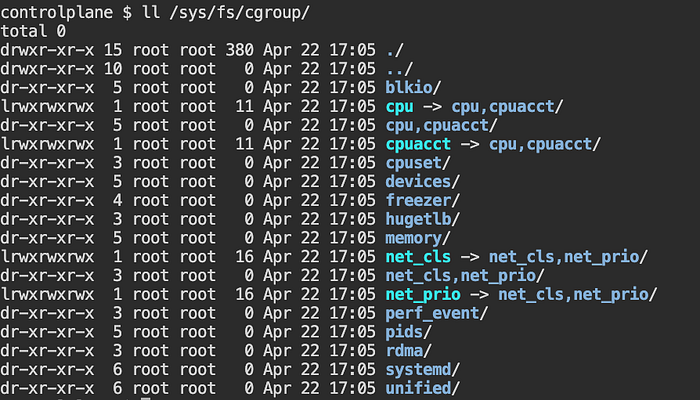
มาดูตัวอย่างการจำกัด CPU และ Memory ผ่าน Kubernetes pod definition กันครับ
apiVersion: v1
kind: Pod
metadata:
name: busybox0
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
name: busybox
resources:
requests:
memory: "10Mi"
cpu: "250m"
limits:
memory: "64Mi"
cpu: "500m"จากตัวอย่าง pod definition มีการระบุ resource limit ไว้คือ memory: "64Mi" และ cpu: "500m" เมื่อลองไปตรวจสอบที่ configuration ของ cgroup ที่ limit เกี่ยวกับ memory ไว้ (/sys/fs/cgroup/memory/<pod cgroup>/memory.limit_in_byte) ก็จะพบว่าค่าที่ได้จะตรงกับสิ่งที่เรากำหนดไว้ใน pod definition
controlplane$ cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod2e399b9a_350d_4aaf_b379_1dcae4bdee41.
slice/memory.limit_in_bytes
67108864
# 1 Mebibyte (MiB)= 1,048,576 bytes ;
# 64Mi = 64 * 1,048,576 = 67,108,864 bytesสำหรับการจำกัด (limit) การใช้งาน CPU นั้นจะมีความซับซ้อนแตกต่างจาก memory เนื่องจากการจำกัดการใช้งาน CPU จะใช้วิธีการควบคุมเวลาของ process ในการเข้าไปใช้งาน CPU โดยใช้ CFS (Completely Fair Scheduler) Bandwidth Control ซึ่งเป็นส่วนหนึ่งของ Linux kernel
โดยการตั้งค่าจะอยู่ภายใน cgroup configuration (/sys/fs/cgroup/cpu/<pod cgroup>/) ภายใต้ 2 ไฟล์ คือ cpu.cfs_period_us และcpu.cfs_quota_us
controlplane$ pwd
/sys/fs/cgroup/cpu/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod2e399b9a_350d_4aaf_b379_1dcae4bdee41.slice
controlplane$ cat cpu.cfs_quota_us
50000
controlplane$ cat cpu.cfs_period_us
100000การที่เรากำหนด pod limit cpu: "500m" มันก็คือการบ่งบอกว่าใน 1 รอบของ CPU (cpu.cfs_period_us) ในที่นี้คือ 100,000 us หรือ 100 ms , pod นี้จะสามารถเข้าใช้งาน CPU resource ได้แค่ 50,000 us หรือ 50 ms นั้นเอง
หากต้องการอ่านการทำงานของ CPU Limit อย่างละเอียด สามารถอ่านได้จากบทความของน้องนนท์ Nontawat Numor ได้เลยครับ CPU Limit บน Kubernetes คือ สิ่งที่สร้างความปวดหัวให้กับ LINE MAN Wongnai
3. Services และ Kubernetes Networking
ใน Kubernetes, Service เป็นวิธีหนึ่งที่จะทำให้เราสามารถ expose กลุ่มของ pod ผ่านระบบ network ซึ่งทำให้ pod อื่นๆ หรือ client จากภายนอก cluster สามารถเชื่อมต่อไปยังกลุ่มของ pod นั้นๆได้
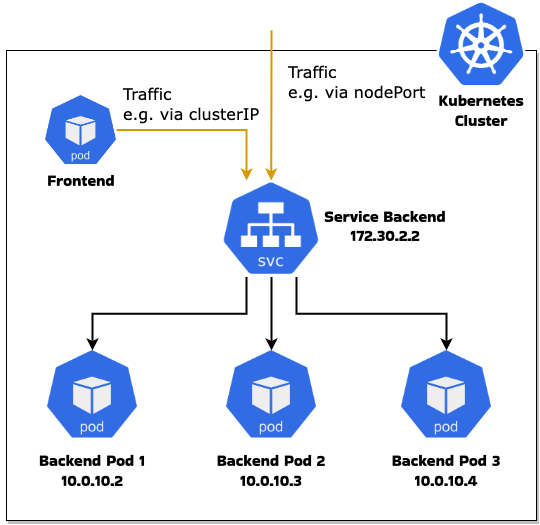
เบื้องหลังของ service ในการควบคุมเส้นทางของแต่ละ request เกิดจากกลไกที่เรียกว่า packet filtering ของ Linux kernel โดย kernel ที่หลายๆ คนอาจจะรู้จักกันดีนั้นคือ Netfilter

ปัจจุบันเราสามารถเลือกรูปแบบตั้งค่าการทำงานของ service ได้ 3 โหมด (3 เครื่องมือของ Linux):
- Iptables: เป็นโหมด default ที่จะถูกกำหนดลงบน kube-proxy หากไม่ได้ปรับแต่งใดๆ ในตอนติดตั้ง cluster โดยหลักการเลือกส่ง request ไปยัง pod จะเป็นลักษณะที่เทียบเท่ากับการสุ่ม (random)
- IPVS: มีลักษณะที่คล้ายกับ iptables แต่กลไกการเลือก pod ในการส่ง request จะมีประสิทธิภาพที่ดีกว่า รองรับ throughput ได้สูงกว่า และยังมีตัวเลือกในการ balance traffic ได้หลายรูปแบบ เช่น Round Robin, Least Connection Source/Destination Hashing เป็นต้น
- nftables: โหมดนี้เป็นโหมดใหม่ล่าสุดที่คาดว่าจะมาแทนที่ iptables ในอนาคต Kubernetes จะรองรับโหมดนี้ตั้งแต่ version 1.29 เป็นต้นไป โดยกลไกเลือก pod ก็จะยังคงเป็นการสุ่ม (random) แต่จะมีประสิทธิภาพที่ดีกว่า iptables
สามารถอ่านรายละเอียดการเปรียบเทียบ iptables กับ ipvs ได้จากบทความ Kubernetes Best Practices ที่ทุกคนควรรู้ EP.1
ตัวอย่างคำสั่งในการตรวจสอบ iptables rule
controlplane $ kubectl get service -A # list kubernetes service
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 13d
controlplane $ kubectl get endpoints -A # list kubernetes endpoint ที่จะถูกไปผูกกับ service
NAMESPACE NAME ENDPOINTS AGE
default kubernetes 172.30.1.2:6443 13d
kube-system kube-dns 192.168.1.2:53,192.168.1.3:53,192.168.1.2:53 + 3 more... 13d
controlplane $ iptables -t nat -L KUBE-SERVICES # list rule ที่เกี่ยวข้องกับ kubernetes service ทั้งหมด
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-SVC-TCOU7JCQXEZGVUNU udp -- anywhere 10.96.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain
KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- anywhere 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain
KUBE-SVC-JD5MR3NA4I4DYORP tcp -- anywhere 10.96.0.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- anywhere 10.96.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:https
controlplane $ iptables -t nat -L KUBE-SVC-JD5MR3NA4I4DYORP # list endpoint และ rule ของ service ที่ต้องการ <ex. KUBE-SVC-JD5MR3NA4I4DYORP>
Chain KUBE-SVC-JD5MR3NA4I4DYORP (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !192.168.0.0/16 10.96.0.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
KUBE-SEP-UG4OSZR4VSWZ27C5 all -- anywhere anywhere /* kube-system/kube-dns:metrics -> 192.168.1.2:9153 */ statistic mode random probability 0.50000000000
KUBE-SEP-I63X27HX2ZZBGI74 all -- anywhere anywhere /* kube-system/kube-dns:metrics -> 192.168.1.3:9153 */ส่วนการจัดการ Kubernetes networking ในส่วนอื่นๆ อย่างเช่น
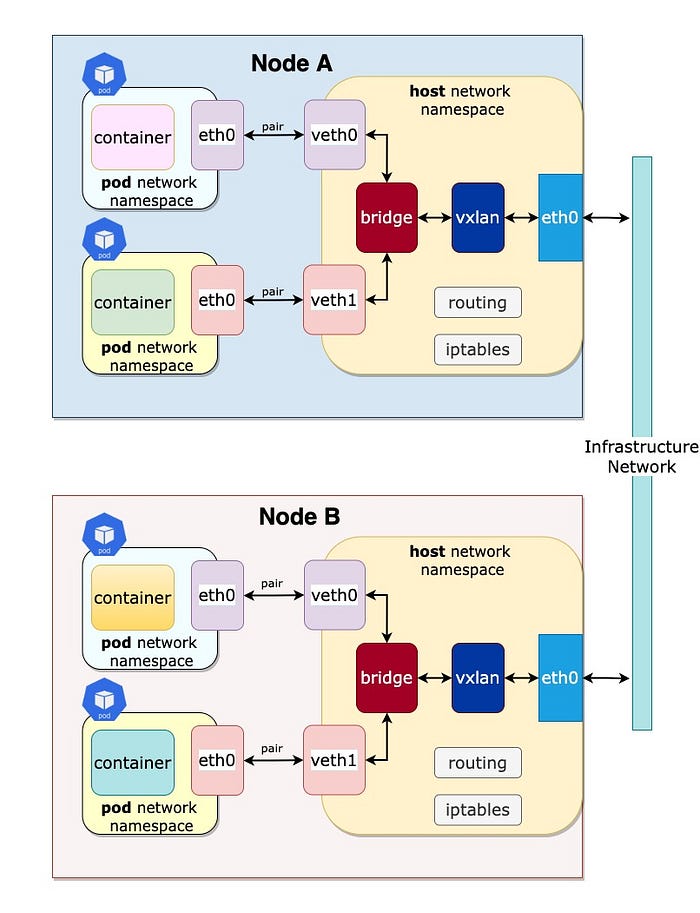
- การสร้าง tunnel ระหว่าง namespace (pod namespace ไปยัง root namespace)
- การ bridge network เพื่อให้ pod หรือ container สามารถเชื่อมต่อกันได้ภายในโหนดเดียวกันหรือระหว่างโหนด
ทั้งหมดนี้มาจากเครื่องมือต่างๆ บน Linux เช่น:
- Network namespace (netns)
- Virtual Ethernet (veth)
- Iproute2
- NAT (iptables) -> Netfilter
- Bridge (brctl)
- Virtual eXtensible Local Area Networking (vxlan)
อย่างไรก็ตาม เราไม่จำเป็นต้องจัดการเครื่องมือเหล่านี้ด้วยตัวเอง เพราะเราสามารถให้ CNI (Container Network Interface) plugin เข้ามาช่วยจัดการให้แบบอัตโนมัติได้
4. Network Policy
Network Policy ทำหน้าที่เสมือน virtual firewall ภายใน Kubernetes ที่สามารถกำหนด network rules หรือ access control lists (ACLs) ได้ว่าจะอนุญาตหรือไม่อนุญาตให้ pod ใดๆ สามารถเชื่อมต่อกันได้บ้าง โดย Network Policy จะทำงานอยู่บน Network Layer 3 และ 4 ซึ่งหมายความว่าจะสามารถควบคุมการเชื่อมต่อได้ในระดับ IP address และ port number เท่านั้น
โดยปกติแล้ว Kubernetes ไม่ได้มีความสามารถของ Network Policy ติดตั้งมาให้ตั้งแต่ต้น ข้อกำหนดเบื้องต้นเพื่อที่จะสามารถเริ่มใช้งาน Network Policy ได้นั้น ใน Kubernetes cluster ของเราจำเป็นต้องมี CNI Plugin ที่รองรับการทำงานของ Network Policy ติดตั้งอยู่ในทุก node เสียก่อน จึงจะสามารถเริ่มใช้งาน Network Policy ได้
โดย CNI Plugin ที่รอบรับ network policy เช่น
- Weave
- Calico
- Cilium
- AWS VPN CNI
ถึงตรงนี้คงจะพอเดาออกแล้วใช่ไหมครับ หากเป็นเรื่องของการควบคุม network ใน Kubernetes ก็คงหนีไม่พ้นที่จะต้องอาศัยเครื่องมือของ Linux อีกแน่ๆ ใช่ครับ! เบื้องหลังการทำงานของ Network Policy นั้นคือการใช้ Linux Iptables นั่นเอง
แต่ก็มีบาง network plugin ที่เลือกใช้ eBPF ซึ่งเป็น kernel space ในการควบคุมแทน iptables
มาลองดูตัวอย่างกัน:
// ตัวอย่าง network policy - Deny All
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
// ตัวอย่าง network policy - Allow pod nginx one to two
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-nginx-one-to-nginx-two
spec:
podSelector:
matchLabels:
app: nginx-two
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: nginx-oneIptables rules เมื่อกำหนด Network Policy เรียบร้อยแล้ว:
# result of iptables rule
node01 $ iptables -t filter -L | grep knp # list iptables rule ที่ apply เกี่ยวกับ network policy
Chain cali-pi-_ApjaF4pF4S_O_DH4HKK (4 references)
pkts bytes target prot opt in out source destination
0 0 all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:xGUKUduZ_ss2Hj1Y */ /* Policy default/knp.default.default-deny-all ingress */
Chain cali-po-_ApjaF4pF4S_O_DH4HKK (4 references)
pkts bytes target prot opt in out source destination
0 0 all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:8s6ot2K4WIKjf7Ot */ /* Policy default/knp.default.default-deny-all egress */
Chain cali-pi-_rEzagB5U0FAwb8xNkqO (2 references)
pkts bytes target prot opt in out source destination
0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:qUOWKbyMRonGcXD_ */ /* Policy default/knp.default.allow-from-nginx-one-to-nginx-two ingress */ match-set cali40s:rtrR_19c6daH5ojQ7qk4aC- src MARK or 0x10000
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/05. Persistent Volume (PV) และ Persistent Volume Claim (PVC)
การที่จะทำให้ pod สามารถ mount persistent volume ที่เราต้องการเข้าไปภายใน pod ได้นั้น เราจำเป็นต้องใช้ Kubernetes object ที่ชื่อว่า PersistentVolume (PV) และ PersistentVolumeClaim (PVC)
PersistentVolume (PV)
PV เป็นตัวแทนที่จะบอกกับ cluster นั้นๆ ว่ามี storage resource ประเภทใดให้ pod สามารถใช้งานได้บ้าง ซึ่งภายใน setting ของ PV ก็จะมีการกำหนด directory path, ตำแหน่ง endpoint ของ storage volume หรือ protocol ที่ต้องการเชื่อมต่อไปยัง storage volume เป็นต้น
PV สามารถถูกสร้างได้ 2 รูปแบบ:
1. Static: ให้นึกภาพง่ายๆ คือ เราจำเป็นต้องสร้าง PV ขึ้นมาเอง
2. Dynamic: คือการที่เราสามารถสร้าง storage volume ขึ้นมาแบบ on-demand ได้ โดยที่ไม่ต้องไปสร้าง volume แบบ manual ขึ้นมารอไว้ก่อน ความสามารถนี้จำเป็นต้องอาศัยอีกหนึ่ง Kubernetes object นั่นก็คือ Storage Class
Storage class จะรับหน้าที่ในการติดต่อกับ storage provider ที่รองรับ เพื่อจะสร้าง volume ใหม่ขึ้นมาให้พร้อมทั้งสร้าง PV ขึ้นมาใหม่ให้ด้วย
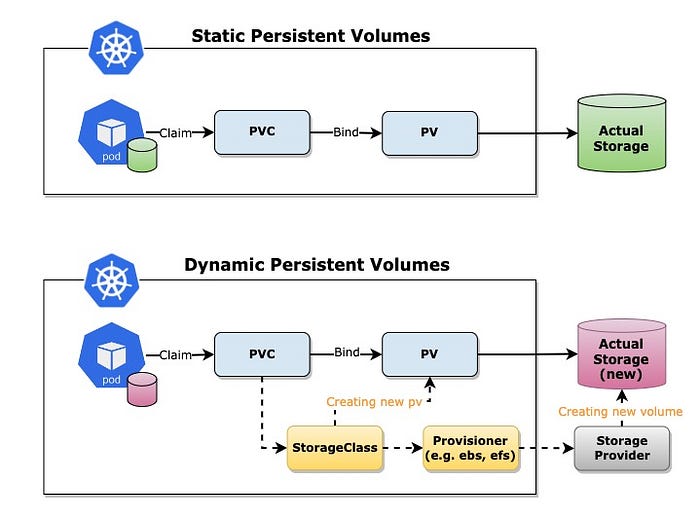
PersistentVolumeClaim (PVC)
PVC จะใช้สำหรับให้ pod ขอ request หรือ claim ใช้งาน storage volume หรือ PV ที่สร้างขึ้นมา ซึ่งจะต้องกำหนดขนาดของ volume ที่ต้องการใช้งานและโหมดในการใช้งาน เช่น ReadWriteOnce, ReadOnlyMany, ReadWriteMany, หรือ ReadWriteOncePod แต่ก็อาจจะขึ้นอยู่กับประเภทของ volume ด้วยเช่นกัน
ขั้นตอนการ mount persistent volume ไปยัง pod:
- สิ่งแรกที่เราต้องสร้างขึ้นมาก่อนบน Kubernetes cluster ก็คือ PV และ PVC [static]
- หลังจากนั้นเมื่อเราสร้าง pod ที่มีการกำหนด claim PVC ไว้, kube-scheduler ก็จะ assign pod ไปยัง worker node ที่พร้อมหรือตามที่กำหนดไว้
- เมื่อ worker node ได้รับคำสั่งแล้ว ก็จะเริ่มสั่งให้ volume plugin ทำการ mount volume ที่ต้องการมาที่ worker node
- ต่อมา volume plugin ก็จะทำการ mount ไปยัง directory ของ pod นั้นต่อและหลังจากนั้นก็จะทำการ start pod ขึ้นมา
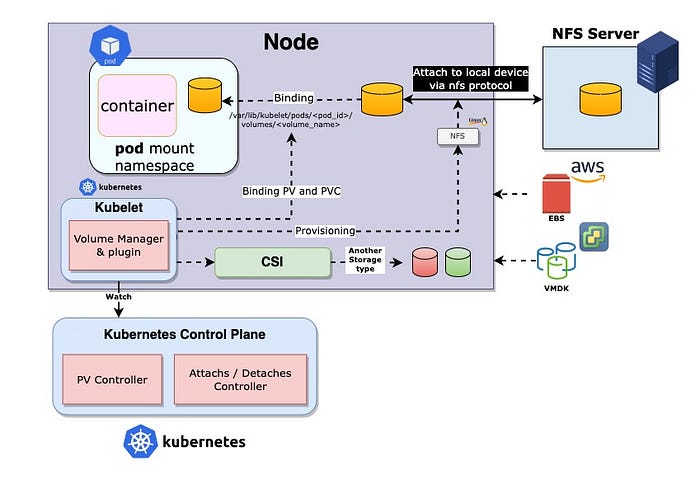
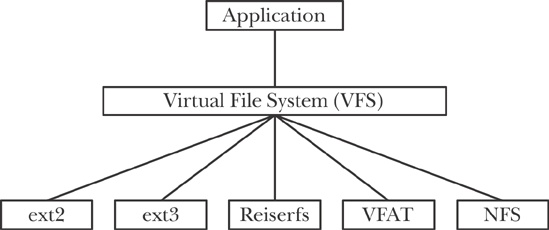
จะเห็นว่าก่อนที่เราจะ mount volume ไปยัง pod ได้นั้น จำเป็นต้อง mount volume มายัง worker node ก่อน ซึ่งกลไกเบื้องหลังก็เกิดจากการทำงานของ Linux kernel ที่ชื่อว่า “Virtual File System (VFS)” ในการช่วยเป็นตัวกลางในระหว่าง userspace และ filesystem driver อย่างเช่น NFS, iSCSI หรือ volume plugin แบบอื่นๆ ที่รองรับ
เราสามารถใช้ Container Storage Interface (CSI) ของแต่ละ product vendor เข้ามาจัดการ storage volume ประเภทอื่นๆ ที่ไม่รองรับบน kubernetes native ได้
ยังมีอีกหลากหลาย Kubernetes object ที่ยังไม่ได้พูดถึง ที่มีเบื้องหลังกลไกมาจาก Linux ยกตัวอย่างเช่น SELinux , Seccomp และ AppArmor ที่ช่วยในการควบคุมนโยบายความปลอดภัยสำหรับ container หรือ pod ผ่าน Kubernetes Pod Security Admission เป็นต้น
Summary
ทุกคนน่าจะเห็นแล้วว่า Kubernetes ได้นำความสามารถที่หลากหลายของ Linux เช่น container, networking และ storage มาผนวกรวมกัน จนทำให้ Kubernetes กลายเป็น container orchestrator ที่สมบูรณ์แบบมาถึงตอนนี้
ดังนั้น ผมจึงมองว่า Linux ยังคงเป็นพื้นฐานสำคัญในการใช้งาน Kubernetes อยู่ การมีความรู้พื้นฐานเกี่ยวกับ Linux ที่ดีจะช่วยให้เราสามารถเข้าใจการทำงานต่างๆ ของ Kubernetes ได้ดียิ่งขึ้น รวมถึงแก้ไขปัญหาต่างๆ ที่เกิดขึ้นบน Kubernetes ได้ง่ายขึ้นด้วย
ผมหวังว่าบทความนี้จะช่วยให้ผู้อ่านได้เข้าใจถึงความสัมพันธ์อันลึกซึ้งระหว่าง Kubernetes และ Linux มากขึ้นนะครับ

